Introduction
Zasper is an open-source High Performance IDE for working with Jupyter notebooks. It’s built from scratch to be:
- 🚀 Blazing fast
- 🧠 Highly concurrent
- 💾 Low on resource usage
- 💥 Crash-resistant, even under heavy loads
It is cross-platform:
- ✅ Fully supported: macOS & Linux
- ⚠️ Limited support: Windows — for the best experience, use via WSL
Benchmarks
How is Zasper better than JupyterLab?
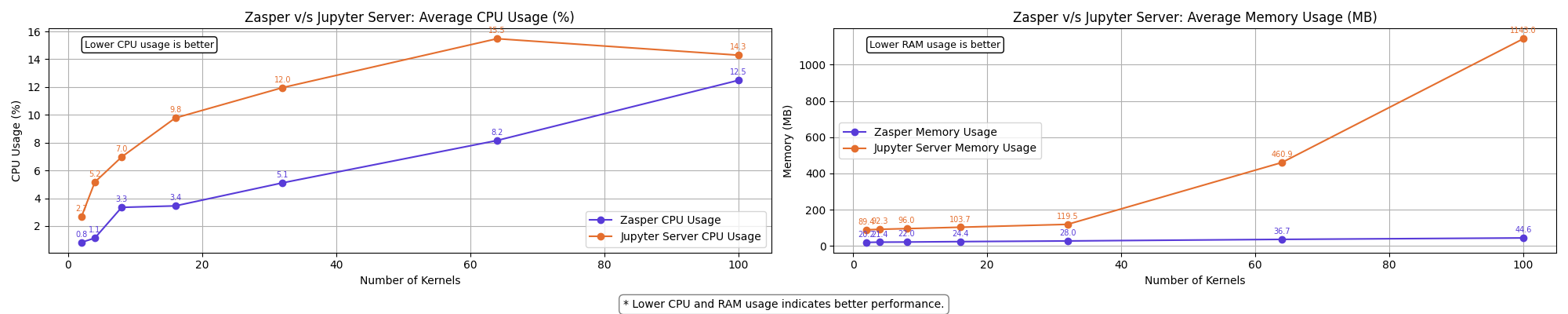
- Up to 5X Less CPU usage
- Up to 40X Less RAM usage
- Higher throughput
- Lower latency
- Highly resilient under very high loads
Benchmark comparison report can be accessed here.
📷 Screenshots
Editor
Terminal
Launcher
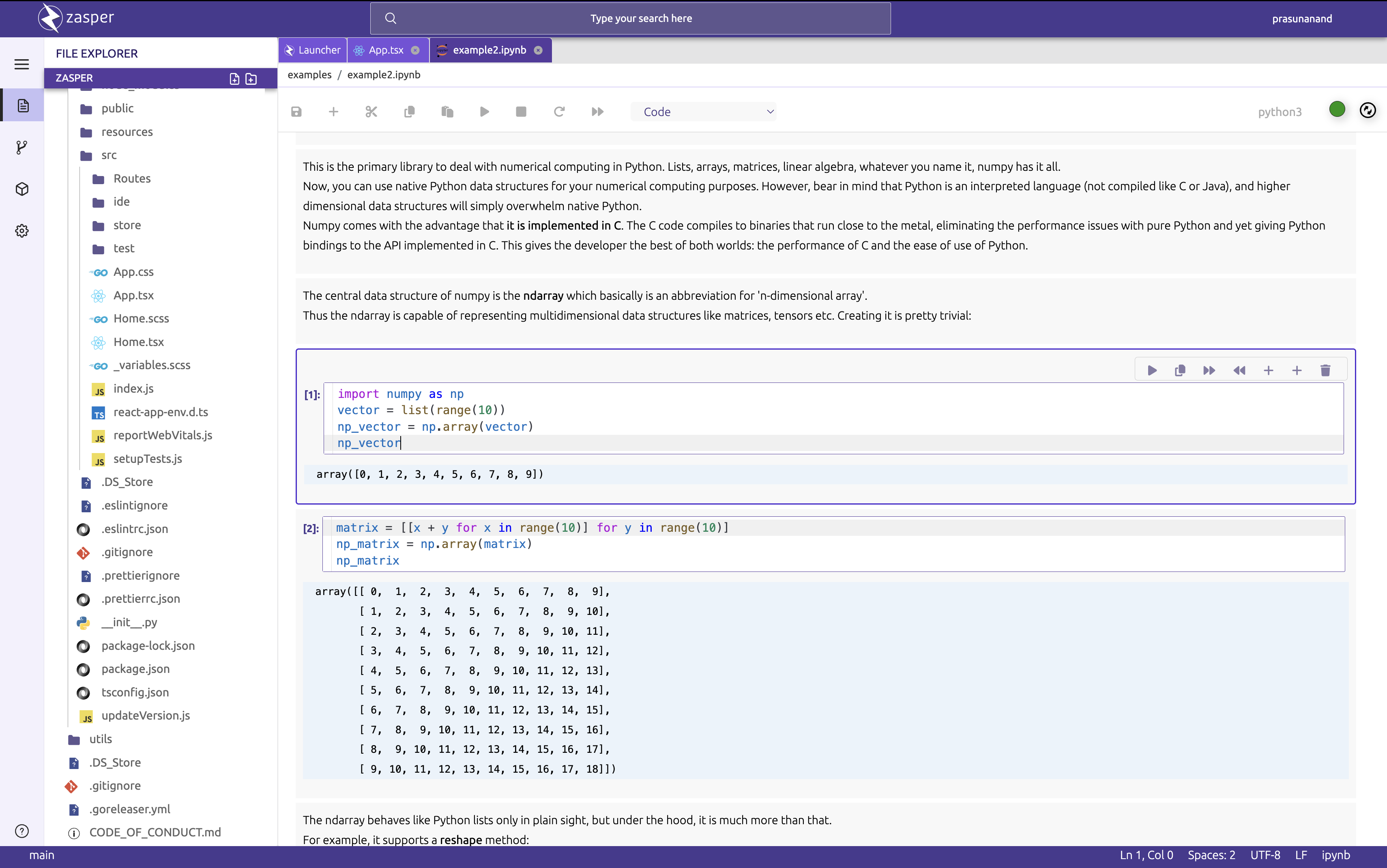
Jupyter Notebook
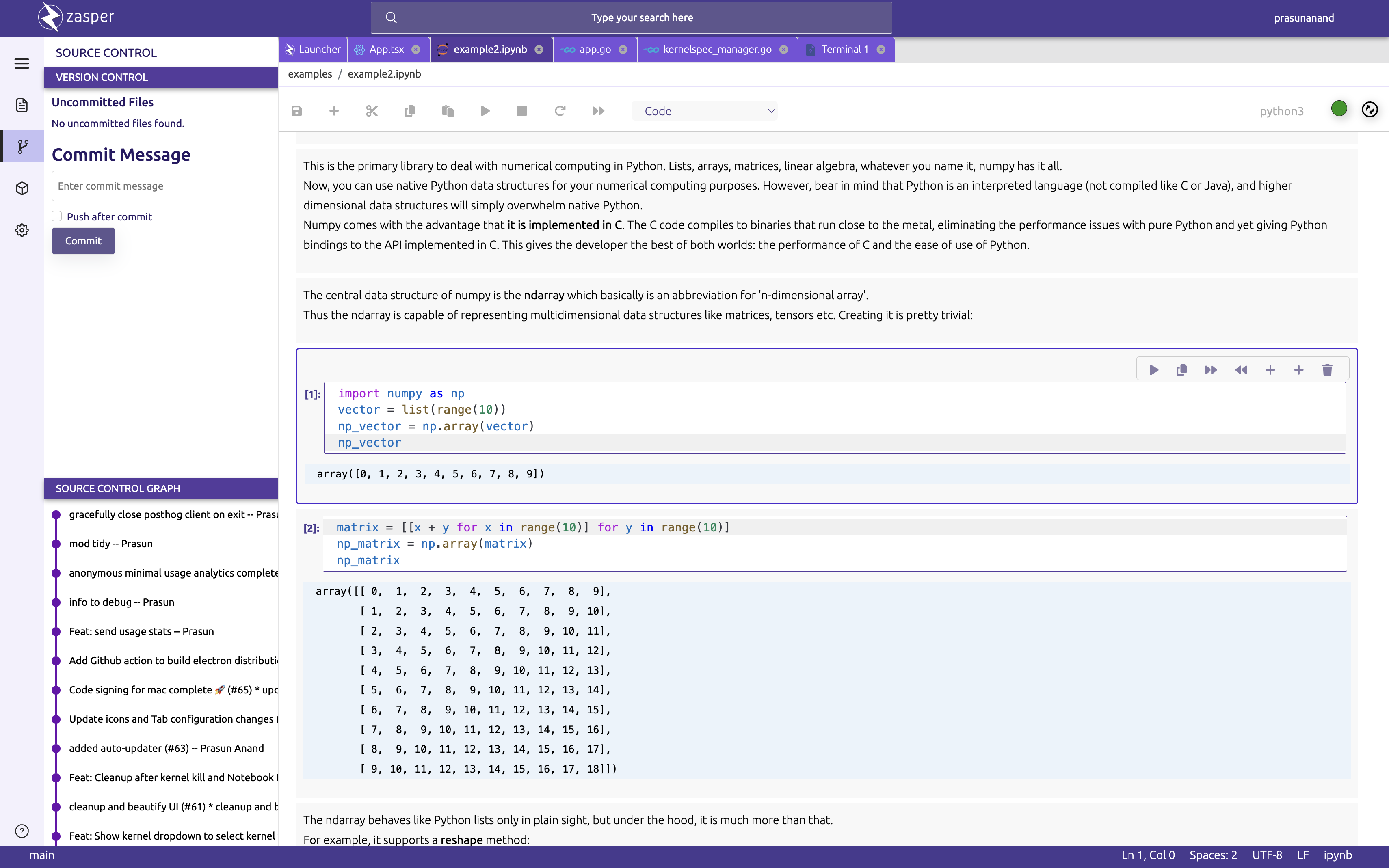
Version Control
Command Palette
Dark Mode